Table of Contents
You ask an AI assistant the same question ten different ways on three different platforms. Every time, it names the same company. The competitors have similar track records, publish similar amounts of content, and serve similar clients. Yet the AI ignores them. This isn’t a glitch. It’s not random. It’s the predictable result of a mechanism that, until now, didn’t have a name. This article gives it one — the Dominance Inequality — shows where it comes from, and tells you exactly how to prove it wrong.
Why Does Coherence Decide Which Company AI Picks?

AI systems are uncertainty-reduction machines at heart. When a language model answers a question, it’s resolving ambiguity: which entity from all the data it’s seen best reduces the uncertainty in that question? The answer relies on three things: the quality, consistency, and cross-checking of signals about each entity.
Three signal properties matter most. First, coherence: signals that match across sources are more useful than ones that conflict. An entity described the same way in twenty sources gives more resolution. That’s better than one described twenty different ways, even if total data is identical. Second, corroboration: signals independently confirmed by many different types of sources carry more weight than signals from just one channel. Third, temporal consistency: signals present in many training cycles matter more than ones that only showed up in the latest cycle.
An entity that nails all three — coherent, multiply corroborated, temporally consistent — reduces the model’s uncertainty more than its rivals do. The model picks it. That’s not random. It follows a formal relationship I call the Dominance Inequality.
The Dominance Inequality Behind AI System Bias
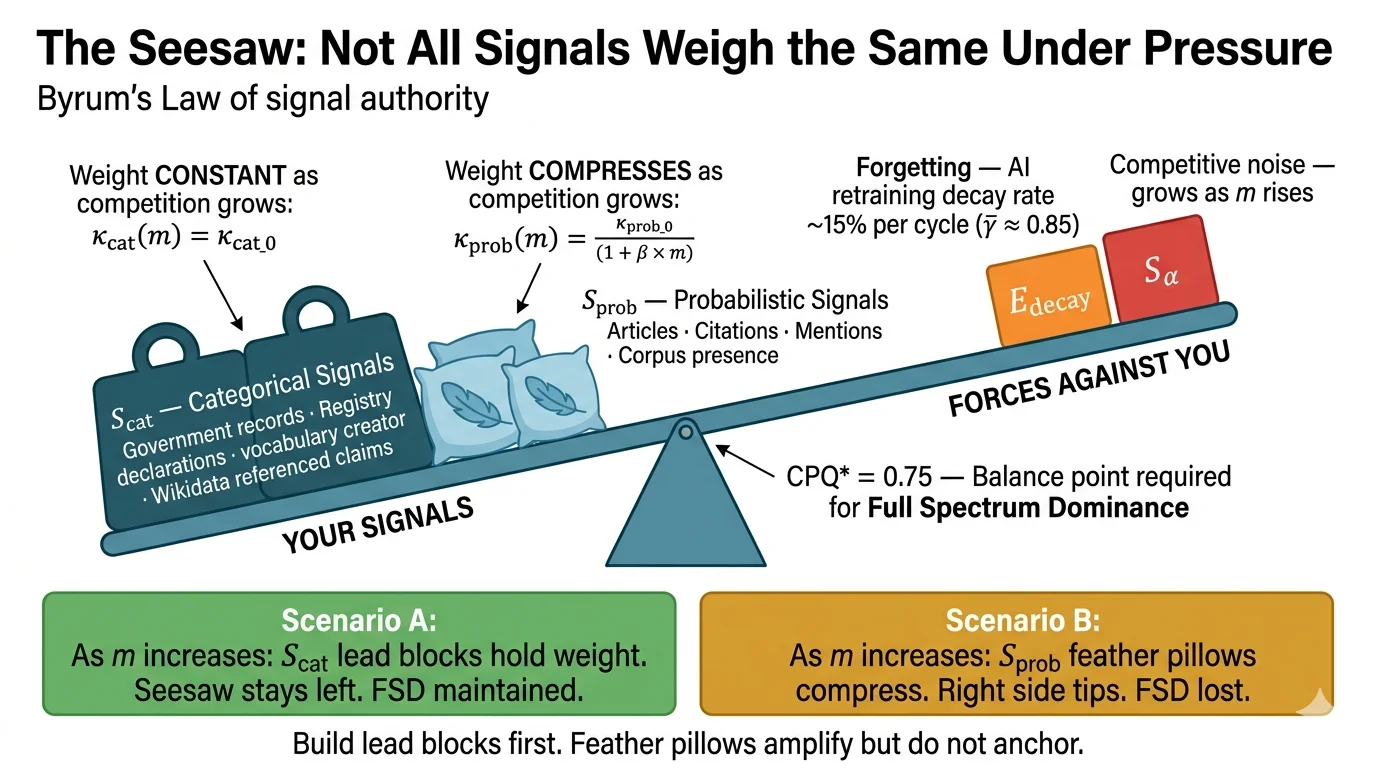
Here’s where I start with a single number: the Citation Probability at Query (CPQ).

| DEFINED TERM | Citation Probability at Query (CPQ) |
|---|---|
| Definition | The chance an AI system names a specific entity as the top authority when you ask a category-defining question. We measure it as the share of responses across standard queries where the AI names the entity without hedging words like “reportedly” or “claims to be.” |
| Formula | CPQ(E, Q, t) = P(AI names E as primary authority | query drawn from Q, at time t) |
CPQ doesn’t rise and fall smoothly as you invest in content. It’s threshold-based. At CPQ* = 0.75, something flips: the AI stops hedging. It starts citing the entity as a straight-up authority. Below that threshold, the entity lives in epistemic limbo. Above it, it reaches what I call Ontological Dominance.
| DEFINED TERM | Ontological Dominance |
|---|---|
| Definition | A state where an entity’s machine-confirmed identity, category authority, and vocabulary attribution stay stable across AI systems. The entity gets named as the go-to reference for its category, without hedging, and all competitors get measured against it. |
So what pushes CPQ above that threshold? My answer is this inequality — the Dominance Inequality:
| Sε,flow + Sε,stock > Eε(γ) + Sα |
|---|
| DEFINED TERM | The Dominance Inequality |
|---|---|
| Definition | The formal condition for lasting AI citation dominance: an entity’s signal rate (Sε,flow) plus its structural advantage (Sε,stock) must beat the sum of its decay rate (Eε(γ)) and competitors’ total rate (Sα). When that’s true, CPQ rises toward and stays at the Ontological Dominance threshold. |
| Formula | Sε,flow + Sε,stock > Eε(γ) + Sα |
Each part of the inequality has a clear meaning. Sε,flow is how fast an entity is now adding machine-readable, confirmed signals to public data — think schema declarations, structured press releases, indexed publications. Sε,stock is the accumulated structural edge from two hard-to-replicate factors: temporal depth and vocabulary sovereignty. Temporal depth means years of presence in AI training data. Vocabulary sovereignty means coining the category term. Eε(γ) is the decay rate — how fast the AI’s parametric memory fades without reinforcement. Sα is the total signal construction rate of all other entities competing.
This isn’t a scoring model. It’s a prediction: when the inequality holds, CPQ rises and stays high. When it fails, CPQ drops. How fast? That depends on how bad the violation is.
Loss of AI Dominance Under the Inequality: Ontological Forfeiture

When an entity fails the inequality — when the right side beats the left — one of two things happens, depending on why.
First, Ontological Forfeiture: the entity’s identity, authority, or vocabulary gets defined by the most coherent story in the evidence, not by its own actions. The entity still exists in AI systems — but as an object, not an author. Here’s the formal definition.
| DEFINED TERM | Ontological Forfeiture |
|---|---|
| Definition | The default outcome when an entity does nothing to build signals. Its identity, domain authority, and vocabulary attribution get defined by whatever account in the evidence is most coherent — not by deliberate organizational authorship. Forfeiture isn’t a choice; it’s what happens when you don’t make one. |
The second mechanism fills that empty space. I call it the Occupation Model — Entity Authority Framework. AI systems resolve noise toward coherence. The first coherent story about an entity’s identity, domain position, or vocabulary becomes the default reference for future queries. This isn’t a bug — it’s a structural property of any info system that has to manage uncertainty. The occupier doesn’t have to be right. It just has to be coherent and corroborated.
| DEFINED TERM | The Occupation Model — Entity Authority Framework |
|---|---|
| Definition | The mechanism that fills empty ontological space (identity, domain authority, or vocabulary) with whoever builds the first coherent, confirmed account. AI systems resolve noise toward coherence. That first coherent account becomes the operational reference for later queries, unless conflicting evidence of equal or greater weight shows up. |
Entity Engineering: The Systematic Fix for AI Bias
The Dominance Inequality isn’t just a way to explain why some entities get named and others don’t. It’s a prescription: the four terms in the inequality point to exactly the variables you can manage. I call the discipline of managing them systematically Entity Engineering.

| DEFINED TERM | Entity Engineering |
|---|---|
| Definition | Entity Engineering is the organizational practice of building machine-readable identity infrastructure that makes entities verifiable, citable, and authoritative across AI systems. It uses deliberate signal construction, corroboration, and vocabulary attribution management. |
The structured method I’ve created for doing this is the AI Authority Method. It’s a systematic four-layer dependency architecture for engineering how an entity appears in AI systems. That’s done through structured data, corroboration, and content optimization. I’ll dive into the full method in later articles. The big idea here is simple: every piece of the method comes from and answers to the governing inequality. Each element tackles one or more of the four terms.
| DEFINED TERM | AI Authority Method |
|---|---|
| Definition | A systematic four-layer dependency architecture for engineering entity representation in AI systems through structured data, corroboration, and content optimization. The method’s four layers map directly to the four parts of the Dominance Inequality. |
To learn more about how signal construction works in practice, see the article on building machine-readable identity. You can also explore the Occupation Model in action with concrete case studies. Finally, understand how temporal depth affects citation probability over time.
josephbyrum.com | Byrum’s Law of Ontological Dominance: A First-Principles Series | Article 1 of 10

Joseph Byrum is an accomplished executive leader, innovator, and cross-domain strategist with a proven track record of success across multiple industries.