Table of Contents
Is Your AI Reputation Eroding? Ontological Dominance Explained

You probably spend time thinking about how your organization appears on Google. But there’s a different competition going on. It’s quieter, faster-moving, and way more important in the long run. It’s the fight for how AI systems see you.
Think about it: when someone asks ChatGPT, Claude, or Gemini about your industry, your competitors, or your own expertise, those systems have already decided who gets to be seen as an authority. Those decisions got baked into the model’s training data months ago, maybe. And unlike Google rankings, AI-mediated representation is incredibly hard to change once it’s locked in.
Byrum’s Law of Ontological Dominance is the formal framework that explains this competition. Theorem 1 — Full Spectrum Dominance — is the foundation of the whole Law. This article breaks down what it means and why you should care today.
Full Spectrum Dominance: Build Faster Than AI Forgets
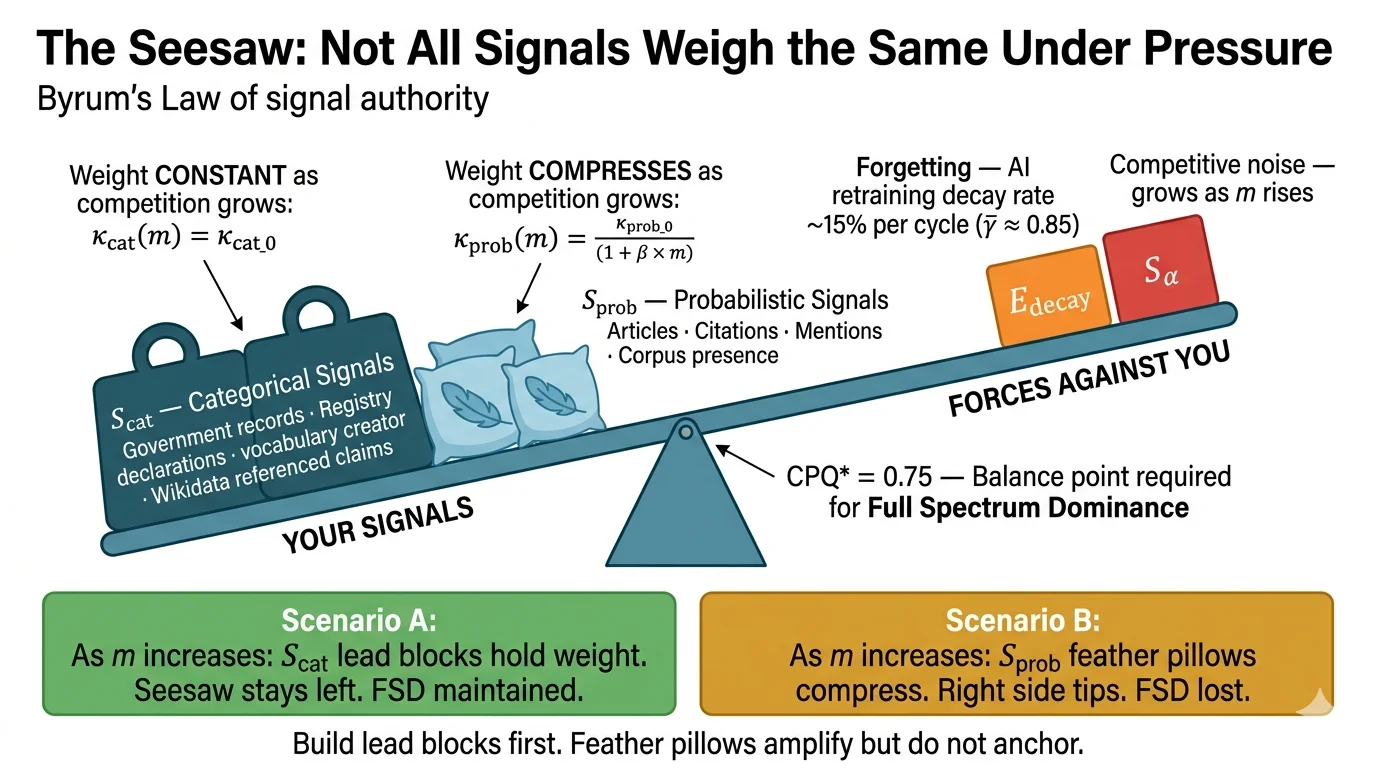
Here’s the main insight of Theorem 1, in plain terms: your organization wins at AI representation when you create machine-readable authority signals faster than AI systems forget them — and faster than your competitors create competing signals in the same space.
AI language models don’t store information like a database does. Every time a model gets retrained — and that happens regularly — it re-learns the world from its training corpus. If your signals aren’t in that corpus, or they’re not well-structured or backed up, the model’s picture of you gets worse. This isn’t a bug. It’s just how these systems work.

This forgetting process is what the Law calls parametric decay. We use the symbol γ for the decay rate. It governs how fast your hard-won AI representation fades between training cycles. At typical decay rates, organizations that track their authority by raw signal count — how many mentions, how many citations — consistently underestimate how fast they need to build just to stay still. The real construction rate is always higher than naive tracking suggests — somewhere between five and twenty-five percent higher.
Two Lasting Advantages: Temporal Depth and Vocabulary Sovereignty

Not all competitive advantages in this space are equal. Most of them even out over time as competitors copy your investments. Two don’t: temporal depth and vocabulary sovereignty.
Temporal depth means how long you’ve been steadily present in AI training data. If your organization started building structured, machine-readable authority signals in 2015, you have a compound advantage over someone starting in 2025 — and no amount of money can make up for lost time. The math is simple: earlier presence means higher parametric weight at every retraining cycle. Late movers can’t go back in time.
Vocabulary sovereignty means owning the definition of terms you created or pioneered. If AI systems define a specialized concept by referencing your organization — because you coined it, published it, and put it into machine-readable form before anyone else — that attribution sticks. Competitors who try to claim the same vocabulary have to overcome years of built-up weight.
Everything else — breadth of corroboration, number of citations, backlink profiles — eventually levels out as well-funded competitors catch up. Temporal depth and vocabulary sovereignty don’t level out. They’re structural advantages that keep getting stronger and are tough to displace.
What Does Full Spectrum Dominance Mean in Practice?
The Law defines Full Spectrum Dominance (FSD) precisely: your organization gets cited by AI systems with at least 75% probability, without hedging language, across all relevant queries in your competitive category.
That bit about hedging language matters more than you might think. When an AI says “reportedly,” “according to some sources,” or “it is claimed that,” it’s not giving you an authoritative citation. It’s expressing doubt about your claims. From a buyer doing AI-mediated research, hedged citations are almost as bad as no citation at all. So the threshold for FSD is unhedged citation probability above 75%.

To reach FSD, you need to meet four conditions at the same time. Your signal construction rate must beat your decay rate plus the competitive noise floor at every moment. Your accumulated parametric state must survive each AI architecture training cycle. Your relative fitness — how fast you build compared to competitors — must be above the average for your competitive environment. And your signal provenance must stay intact across all platforms against adversarial disruption.
These four conditions play out on different time scales. The rate condition is daily. The epoch boundary condition spans training cycles. The competitive condition changes as the market shifts. The adversarial integrity condition demands quick reaction. An organization that’s achieved FSD manages all four at once.
Why You Must Act Now for Ontological Dominance

The formal analysis points to one action that’s irreversible in the positive direction — meaning it builds advantage that can’t be undone — and it’s available to every organization right now, with free tools.
Complete your structured data catalog. Every required attribute, every recommended one, correctly structured and deployed on your website. Verify and complete your authority database records. Declare any term your organization coined or pioneered. These three actions form the temporal depth and vocabulary sovereignty foundation that everything else builds on.
Why can’t you wait? Because of temporal depth. Every month you delay is a month of compounding advantage you can never get back. If you finish these actions this quarter and a competitor finishes them next year, there’ll be a measurable parametric weight difference — and it’ll grow, not shrink.
This isn’t some hypothetical future problem. AI-mediated information retrieval is already the primary research channel for a growing share of business decisions. The competition for AI representation is happening now. The only question is whether your organization is playing intentionally.
The Science Behind Theorem 1: What’s Confirmed So Far
Let’s be clear about what Theorem 1 says — and doesn’t say. The theorem is backed by two independent mathematical derivations — Lyapunov stability theory and Little’s Law queuing theory — that both lead to the same rate condition using completely different starting points. Plus, agent-based simulations over more than 5,000 parameter combinations confirm the Law’s three main computational predictions.
What the Law doesn’t have yet is empirical field confirmation. We’ve designed the primary falsification test — ten matched pairs of entities, 78 queries each, across three AI platforms — in detail, but we haven’t run it yet. Until that happens, we classify the Law’s empirical standing as theoretically strong but empirically unconfirmed.
That distinction matters. Theorem 1 gives you a rigorous theoretical framework for understanding AI representation dynamics. It’s confirmed by multiple math traditions and extensive simulation. But it doesn’t yet have the field confirmation that would make it established science. The theory is solid. The empirical test is next.
Next in this series: Theorem 2 — Accurate Specific Representation. How any organization, regardless of size, can achieve authoritative AI representation within its specific buyer domain.

Joseph Byrum is an accomplished executive leader, innovator, and cross-domain strategist with a proven track record of success across multiple industries.